Introduction
RAID is an acronym which stands for Redundant Array of Independent Disks. It combines multiple disk drives into a logical unit. As its name implies, it provides redundancy which allows continuous access to data should a disk drive fail. When a server wants to store data it sends a write command to the storage array with the data to be stored and a logical unit number (LUN) identifying where to place the data. When the server wants to retrieve that data, it sends a read request to the storage array, again referencing the LUN from which to retrieve the data. The server doesn’t realize that the data isn’t being stored on a disk drive but on a series of disk drives. It doesn’t really care just as long as it can store and retrieve the data. A RAID storage array is a virtual storage device. Although virtualization in the server and network space is somewhat new, virtualization in the data space has been around for quite some time.
RAID Levels
Depending on the level of redundancy and performance required, data is distributed across the disk drives in one of several ways, most of which provide protection against sector or whole drive failures. Let’s take a look at the more popular RAID levels.
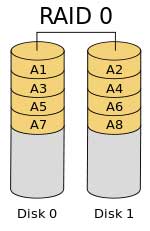 RAID 0 – RAID 0 is a bit misleading as it provides no redundancy at all and as a result, no protection against drive failures. RAID 0 is really a data distribution scheme to increase write performance. In this scheme, data is stripped across a set of disk drives so that each drive only has to store a portion of the data and, therefore, the data as a whole is written in less time than if it were written to a single disk drive. The downside to RAID 0 is the opportunity for a disk failure is doubled.
RAID 0 – RAID 0 is a bit misleading as it provides no redundancy at all and as a result, no protection against drive failures. RAID 0 is really a data distribution scheme to increase write performance. In this scheme, data is stripped across a set of disk drives so that each drive only has to store a portion of the data and, therefore, the data as a whole is written in less time than if it were written to a single disk drive. The downside to RAID 0 is the opportunity for a disk failure is doubled.
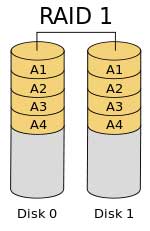 RAID 1 – RAID 1 requires at least two drives and provides redundancy by mirroring the data on a second drive or on a second set of drives. Therefore, if a drive fails, it is abandoned and the data is referenced from its mirrored drive. Subsequent writes are then only written to the surviving drive pair until the failed drive is replaced and rebuilt with the data from the surviving drive. Should the surviving drive fail before the failed drive is replaced and reloaded with the mirrored data, an unrecoverable error is said to have occurred. . RAID 10 – RAID 10 is a combination of RAID 1 and RAID 0. In RAID 10, data is stripped across a set of disk drives and the data on that set of drives is mirrored on another set of disk drives. RAID 10 gives the system higher performance writes, as in RAID 0, as well as data protection from mirroring as in RAID 1. The downside to RAID 10 is the cost of a larger set of disk drives.
RAID 1 – RAID 1 requires at least two drives and provides redundancy by mirroring the data on a second drive or on a second set of drives. Therefore, if a drive fails, it is abandoned and the data is referenced from its mirrored drive. Subsequent writes are then only written to the surviving drive pair until the failed drive is replaced and rebuilt with the data from the surviving drive. Should the surviving drive fail before the failed drive is replaced and reloaded with the mirrored data, an unrecoverable error is said to have occurred. . RAID 10 – RAID 10 is a combination of RAID 1 and RAID 0. In RAID 10, data is stripped across a set of disk drives and the data on that set of drives is mirrored on another set of disk drives. RAID 10 gives the system higher performance writes, as in RAID 0, as well as data protection from mirroring as in RAID 1. The downside to RAID 10 is the cost of a larger set of disk drives.
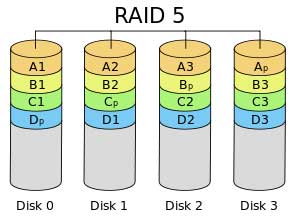 RAID 5 – RAID 5 solves the higher cost of the combined performance and reliability found in RAID 10. In RAID 5 data is distributed across a set of drives, as in RAID 0, yielding the higher performance. However, the cost of redundancy is minimized by requiring only one extra disk drive. This drive is for parity data. When data is stripped across the drive set, parity is also generated by an exclusive OR Boolean function applied to each data element and saved on the parity drive. Should a drive fail, it can be rebuilt with the data from the remaining drives. The missing data element is regenerated using the information in the parity drive. This not only allows the system to rebuild a replacement drive but to also operate without the replacement drive, albeit at a slower read pace as the system must regenerate the missing data on each read. Although an extra drive is used for parity, the parity element is really distributed throughout the drive set so no one drive contains only parity information as can be seen in the RAID 5 diagram below. The downside to RAID 5 is that each disk drive is read quite extensively to rebuild a failed drive. If the heavy reading workload causes a second drive to fail all data now becomes unrecoverable. Today’s single disk drive capacity is up to 4 terabytes of data. Rebuilding a 4 terabyte drive can take many hours. The larger the drive, the longer the rebuild time, and the more likely the system will lose a second drive resulting in data loss.
RAID 5 – RAID 5 solves the higher cost of the combined performance and reliability found in RAID 10. In RAID 5 data is distributed across a set of drives, as in RAID 0, yielding the higher performance. However, the cost of redundancy is minimized by requiring only one extra disk drive. This drive is for parity data. When data is stripped across the drive set, parity is also generated by an exclusive OR Boolean function applied to each data element and saved on the parity drive. Should a drive fail, it can be rebuilt with the data from the remaining drives. The missing data element is regenerated using the information in the parity drive. This not only allows the system to rebuild a replacement drive but to also operate without the replacement drive, albeit at a slower read pace as the system must regenerate the missing data on each read. Although an extra drive is used for parity, the parity element is really distributed throughout the drive set so no one drive contains only parity information as can be seen in the RAID 5 diagram below. The downside to RAID 5 is that each disk drive is read quite extensively to rebuild a failed drive. If the heavy reading workload causes a second drive to fail all data now becomes unrecoverable. Today’s single disk drive capacity is up to 4 terabytes of data. Rebuilding a 4 terabyte drive can take many hours. The larger the drive, the longer the rebuild time, and the more likely the system will lose a second drive resulting in data loss.
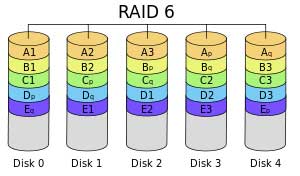 RAID 6 – RAID 6 was developed to overcome the shortcoming of RAID 5. If using large capacity drives, it is recommended that RAID 6 be implemented. RAID 6 used double parity so that two drives can fail and the system still has enough information to rebuild both drives. As in RAID 5, the parity is distributed throughout the drive set. . JBOD – JBOD is an acronym that stands for Just a Bunch Of Disks. It’s not a RAID level at all but is worth addressing in the RAID discussion. JBODs address the need for capacities greater than can be found on a single disk drive but provide nothing in the way of redundancy. There is no algorithm support for stripping, mirroring, or parity. It’s simply an inexpensive way to provide for large capacity storage.
RAID 6 – RAID 6 was developed to overcome the shortcoming of RAID 5. If using large capacity drives, it is recommended that RAID 6 be implemented. RAID 6 used double parity so that two drives can fail and the system still has enough information to rebuild both drives. As in RAID 5, the parity is distributed throughout the drive set. . JBOD – JBOD is an acronym that stands for Just a Bunch Of Disks. It’s not a RAID level at all but is worth addressing in the RAID discussion. JBODs address the need for capacities greater than can be found on a single disk drive but provide nothing in the way of redundancy. There is no algorithm support for stripping, mirroring, or parity. It’s simply an inexpensive way to provide for large capacity storage.
Application
Storage arrays with various RAID levels are used extensively in many applications today. It is often used in deployed applications in rugged environments for data acquisition. The most common environment is on an airborne platform or in a ground station to received collected data from an airborne platform. Data collection sensors have evolved to provide greater resolution which means more data to store. At the same time, disk drive capacities have increased while costs have declined. This has allowed RAID to become the technology of choice for data acquisition applications. CP Technologies offers rugged storage arrays compliant and certified to the rugged MIL-STD-810G standard providing assurance that your data storage is protected in certain harsh environments. The CP Technologies rugged storage arrays support all RAID levels discussed here and are housed in a 2U high 19 inch rack mount enclosure with capacities up to 48 terabytes. For greater capacities, up to seven additional enclosures can be added to extend the total capacity under a single RAID group to 384 terabytes of data. Graphics for this blog article attributed to Colin M.L. Burnett.